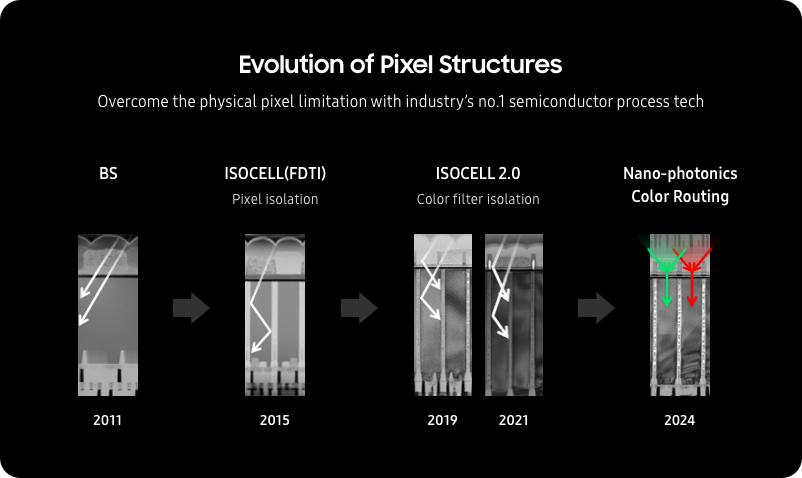
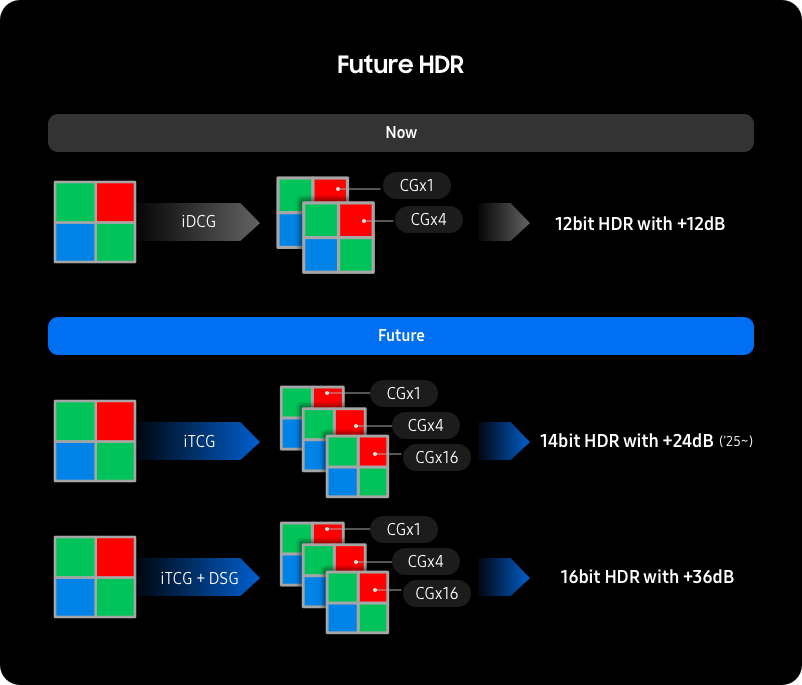
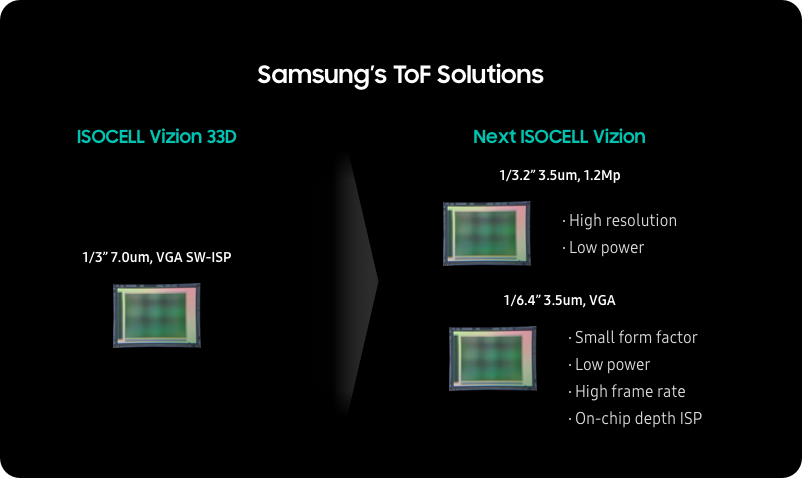
The symposium has many co-located conferences with talks and papers of interest to image sensors community. Short courses on 3D imaging, image sensors and camera calibration, image quality quantification, ML/AI for imaging and computer vision are also being offered.
Please visit the symposium website at https://www.imaging.org/site/IST/IST/Conferences/EI/EI2023/EI2023.aspx for full program. Some interesting papers and talks are listed below.
Evaluation of image quality metrics designed for DRI tasks with automotive cameras, Valentine Klein, Yiqi LI, Claudio Greco, Laurent Chanas, and Frédéric Guichard, DXOMARK (France)
Driving assistance is increasingly used in new car models. Most driving assistance systems are based on automotive cameras and computer vision. Computer Vision, regardless of the underlying algorithms and technology, requires the images to have good image quality, defined according to the task. This notion of good image quality is still to be defined in the case of computer vision as it has very different criteria than human vision: humans have a better contrast detection ability than image chains. The aim of this article is to compare three different metrics designed for detection of objects with computer vision: the Contrast Detection Probability (CDP) [1, 2, 3, 4], the Contrast Signal to Noise Ratio (CSNR) [5] and the Frequency of Correct Resolution (FCR) [6]. For this purpose, the computer vision task of reading the characters on a license plate will be used as a benchmark. The objective is to check the correlation between the objective metric and the ability of a neural network to perform this task. Thus, a protocol to test these metrics and compare them to the output of the neural network has been designed and the pros and cons of each of these three metrics have been noted.
Designing scenes to quantify the performance of automotive perception systems, Zhenyi Liu1, Devesh Shah2, Alireza Rahimpour2, Joyce Farrell1, and Brian Wandell1; 1Stanford University and 2Ford Motor Company (United States)
We implemented an end-to-end simulation for perception systems, based on cameras, that are used in automotive applications. The open-source software creates complex driving scenes and simulates cameras that acquire images of these scenes. The camera images are then used by a neural network in the perception system to identify the locations of scene objects, providing the results as input to the decision system. In this paper, we design collections of test scenes that can be used to quantify the perception system’s performance under a range of (a) environmental conditions (object distance, occlusion ratio, lighting levels), and (b) camera parameters (pixel size, lens type, color filter array). We are designing scene collections to analyze performance for detecting vehicles, traffic signs and vulnerable road users in a range of environmental conditions and for a range of camera parameters. With experience, such scene collections may serve a role similar to that of standardized test targets that are used to quantify camera image quality (e.g., acuity, color).
A self-powered asynchronous image sensor with independent in-pixel harvesting and sensing operations, Ruben Gomez-Merchan, Juan Antonio Leñero-Bardallo, and Ángel Rodríguez-Vázquez, University of Seville (Spain)
A new self-powered asynchronous sensor with a novel pixel architecture is presented. Pixels are autonomous and can harvest or sense energy independently. During the image acquisition, pixels toggle to a harvesting operation mode once they have sensed their local illumination level. With the proposed pixel architecture, most illuminated pixels provide an early contribution to power the sensor, while low illuminated ones spend more time sensing their local illumination. Thus, the equivalent frame rate is higher than the offered by conventional self-powered sensors that harvest and sense illumination in independient phases. The proposed sensor uses a Time-to-First-Spike readout that allows trading between image quality and data and bandwidth consumption. The sensor has HDR operation with a dynamic range of 80 dB. Pixel power consumption is only 70 pW. In the article, we describe the sensor’s and pixel’s architectures in detail. Experimental results are provided and discussed. Sensor specifications are benchmarked against the art.
KEYNOTE: Deep optics: Learning cameras and optical computing systems, Gordon Wetzstein, Stanford University (United States)
Neural networks excel at a wide variety of imaging and perception tasks, but their high performance also comes at a high computational cost and their success on edge devices is often limited. In this talk, we explore hybrid optical-electronic strategies to computational imaging that outsource parts of the algorithm into the optical domain or into emerging in-pixel processing capabilities. Using such a co-design of optics, electronics, and image processing, we can learn application-domain-specific cameras using modern artificial intelligence techniques or compute parts of a convolutional neural network in optics with little to no computational overhead. For the session: Processing at the Edge (joint with ISS).
Computational photography on a smartphone, Michael Polley, Samsung Research America (United States)
Many of the recent advances in smartphone camera quality and features can be attributed to computational photography. However, the increased computational requirements must be balanced with cost, power, and other practical concerns. In this talk, we look at the embedded signal processing currently applied, including new AI-based solutions in the signal chain. By taking advantage of increasing computational performances of traditional processor cores, and additionally tapping into the exponentially increasing capabilities of the new compute engines such as neural processing units, we are able to deliver on-device computational imaging. For the session: Processing at the Edge (joint with ISS).
Analog in-memory computing with multilevel RRAM for edge electronic imaging application, Glenn Ge, Teramem Inc. (United States)
Conventional
digital processors based on the von Neumann architecture have an
intrinsic bottleneck in data transfer between processing and memory
units. This constraint increasingly limits performance as data sets
continue to grow exponentially for the various applications, especially
for the Electronic Imaging Applications at the edge, for instance, the
AR/VR wearable and automotive applications. TetraMem addresses this
issue by delivering state-of-the-art in-memory computing using our
proprietary non-volatile computing devices. This talk will discuss how
TetraMem’s solution brings several orders of magnitude improvement in
computing throughput and energy efficiency, ideal for those AI fusion
sensing applications at the edge. For the session: Processing at the
Edge (joint with ISS).
Processing of real time, bursty and high compute iToF data on the edge (Invited), Cyrus Bamji, Microsoft Corporation (United States)
In indirect time of flight (iToF), a depth frame is computed from multiple image captures (often 6-9 captures) which are composed together and processed using nonlinear filters. iToF sensor output bandwidth is high and inside the camera special purpose DSP hardware significantly improves power, cost and shuffling around of large amounts of data. Usually only a small percentage of depth frames need application specific processing and highest quality depth data both of which are difficult to compute within the limited hardware resources of the camera. Due to the sporadic nature of these compute requirements hardware utilization is improved by offloading this bursty compute to outside the camera. Many applications in the Industrial and commercial space have a real time requirement and may even use multiple cameras that need to be synchronized. These real time requirements coupled with the high bandwidth from the sensor makes offloading the compute purely into the cloud difficult. Thus, in many cases the compute edge can provide a goldilocks zone for this bursty high bandwidth and real-time processing requirement. For the session: Processing at the Edge (joint with ISS)..
A 2.2um three-wafer stacked back side illuminated voltage domain global shutter CMOS image sensor, Shimpei Fukuoka, OmniVision (Japan)
Due to the emergence of machine vision, augmented reality (AR), virtual reality (VR), and automotive connectivity in recent years, the necessity for chip miniaturization has grown. These emerging, next-generation applications, which are centered on user experience and comfort, require their constituent chips, devices, and parts to be smaller, lighter, and more accessible. AR/VR applications, especially demand smaller components due to their primary application towards wearable technology, in which the user experience would be negatively impacted by large features and bulk. Therefore, chips and devices intended for next-generation consumer applications must be small and modular, to support module miniaturization and promote user comfort. To enable the chip miniaturization required for technological advancement and innovation, we developed a 2.2μm pixel pitch Back Side Illuminated (BSI) Voltage Domain Global Shutter (VDGS) image sensor with the three-wafer stacked technology. Each wafer is connected by Stacked Pixel Level Connection (SPLC) and the middle and logic wafers are connected using a Back side Through Silicon Via (BTSV). The separation of the sensing, charge storage, and logic functions to different wafers allows process optimization in each wafer, improving overall chip performance. The peripheral circuit region is reduced by 75% compared to the previous product without degrading image sensor performance. For the session: Processing at the Edge (joint with COIMG).
A lightweight exposure bracketing strategy for HDR imaging without access to camera raw, Jieyu Li1, Ruiwen Zhen2, and Robert L. Stevenson1; 1University of Notre Dame and 2SenseBrain Technology (United States)
A
lightweight learning-based exposure bracketing strategy is proposed in
this paper for high dynamic range (HDR) imaging without access to camera
RAW. Some low-cost, power-efficient cameras, such as webcams, video
surveillance cameras, sport cameras, mid-tier cellphone cameras, and
navigation cameras on robots, can only provide access to 8-bit low
dynamic range (LDR) images. Exposure fusion is a classical approach to
capture HDR scenes by fusing images taken with different exposures into a
8-bit tone-mapped HDR image. A key question is what the optimal set of
exposure settings are to cover the scene dynamic range and achieve a
desirable tone. The proposed lightweight neural network predicts these
exposure settings for a 3-shot exposure bracketing, given the input
irradiance information from 1) the histograms of an auto-exposure LDR
preview image, and 2) the maximum and minimum levels of the scene
irradiance. Without the processing of the preview image streams, and the
circuitous route of first estimating the scene HDR irradiance and then
tone-mapping to 8-bit images, the proposed method gives a more practical
HDR enhancement for real-time and on-device applications. Experiments
on a number of challenging images reveal the advantages of our method in
comparison with other state-of-the-art methods qualitatively and
quantitatively.